Fällt ein Server, Rechenzentrum oder Cloud-Provider-Netzwerk aus, müssen die Daten schnellstmöglich wiederhergestellt werden. Soweit die Theorie zur Desaster-Toleranz. In der Praxis stoßen jedoch relationale Datenbanken an ihre Grenzen, wenn sie geografisch verteilte Daten hochverfügbar vorhalten sollen.
(Quelle: Funtap - Shutterstock)
Katastrophen wie Erdbeben, Feuer, Stromausfall oder Hardware-Schäden können Services unterbrechen und Daten im Rechenzentrum korrumpieren. Solche Auswirkungen kann eine Lösung für Desaster-Toleranz auf ein Minimum begrenzen, indem sie Anwendungen und Daten innerhalb eines für das Geschäft angemessenen Zeitraums nach einem Desaster wiederherstellt. Wie NoSQL-Datenbanken die Ausfalltoleranz auf ein höheres Niveau heben, erklärt Aleksandr Volochnev von DataStax.
Neue Anforderungen im Datenzeitalter
Wie lange sind wir bereit zu warten, bis die App wieder läuft? Länger als drei Sekunden? So viel nahmen 53 Prozent der mobilen Web-Besucher nicht in Kauf. Sie erwarteten ein schnelleres Laden der Seite und brachen ab, fand DoubleClick von Google bereits 2016 heraus. Im heutigen Datenzeitalter, in dem bis 2025 laut IDC-Studie das weltweite Datenvolumen auf 175 Zettabytes ansteigen und bis zu 49 Prozent in Clouds gespeichert wird, zählt jede Zehntelsekunde. Daten müssen stets verfügbar sein, ohne Verzögerungen.
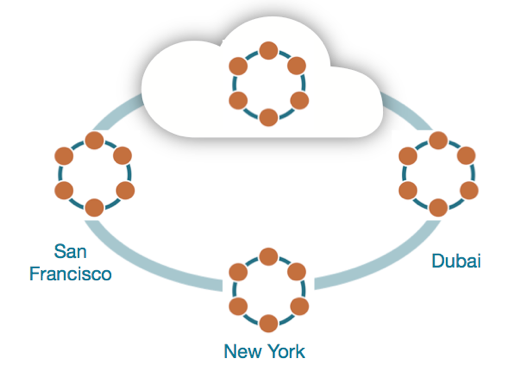
Heute wollen international tätige Unternehmen auch schnell eine Instanz ihres Dienstes direkt in den USA oder beispielsweise in Australien starten. Dafür bietet eine Architektur, die auf relationalen Datenbanken basiert, zu wenig. Denn sie lässt Unternehmen nur die Wahl, ihre Daten an einem einzigen Ort vorzuhalten, was für ihre Kunden bedeutet: Sie müssen warten. Die zweite Variante wäre ein doppelter Datenbankenbetrieb, der sich irgendwann kaum noch managen ließe.
Viele international tätige Unternehmen benötigen global verfügbare Daten.
(Quelle: DataStax)
NoSQL-Datenbank: global verfügbare Daten und skalierbare Apps
Die gesuchte Alternative liefert NoSQL. Solch ein Datenbanksystem macht die Daten global verfügbar, indem es sie auf Servern speichert und über verschiedene Regionen auf unterschiedliche Cloud-Anbieter verteilt. Zusätzliche Kosten entstehen nicht, es tritt höchstens eine gewisse Latenz auf. Apache Cassandra ist ein verteiltes Open-Source-Datenbankmanagementsystem, welches das NoSQL-Datenbankschema genau in diesem Sinne – also ohne relationales Beschreiben der Daten – für die Desaster-Toleranz umsetzt.
Bisher war Apache Cassandra als spaltenorientierte und auf Java basierende NoSQL-Datenbank für andere Szenarien bekannt. Sie kann riesige Datenmengen für Big-Data-Anwendungen verarbeiten und eignet sich als Echtzeit-Datenspeicher für Online-Anwendungen mit vielfältigen Transaktionen. Das schließt extrem skalierbare Echtzeitanwendungen ein, für die sich die Datenbankleistung einfach erhöhen lässt. Für das Verdoppeln fügt man zum Beispiel im laufenden Betrieb einfach so viele Knoten hinzu, wie der Cluster bereits enthalten hat.
NoSQL-Datenbank: Regeln für verteilte Daten
Warum die NoSQL-Datenbank nun einen neuen Standard für Ausfalltoleranz etablieren kann, liegt vor allem daran, dass sie das CAP- oder Brewer's Theorem umsetzt. Dieses beschreibt die Beziehung von Consistency (C), Availability (A) und Partition-Tolerance (P) und geht auf Eric Allen Brewer, Informatikprofessor und Vizepräsident für Infrastruktur bei Google, zurück. Es regelt alle Fragen für verteilte Daten und geht davon aus, dass sich nur zwei der drei Anforderungen (C, A, P) gut aufeinander abstimmen lassen.
Praktische Relevanz besitzen CP- und AP-Systeme, da diese nicht anfällig gegenüber unvermeidlichen Netzwerkausfällen sind. In der CP-Optimierung ist eine Datenbank konsistent und partitionstolerant, aber weniger belastbar. Hochverfügbar und partitionstolerant wird es in der AP-Konfiguration, die aber nur möglicherweise konsistent ist. Das bekannteste AP-System ist das globale Domain Name System (DNS): Es ist unglaublich ausfallsicher und überlebt die Netzwerkpartitionierung problemlos. In diesem Einsatzszenario bleibt Apache Cassandra flexibel, kann die Abfrageposition definieren und das Abfrageverhalten von CP bis AP konfigurieren.
Apache Cassandra setzt das CAP-Theorem optimal um.
Laut dem CAP-Theorem müssen alle Single Points of Failure (SPoF) beseitigt werden. Fallen diese aus, geht auch im System nichts mehr. Jeder Masterknoten einer relationalen Datenbank ist ein SpoF. Mit Apache Cassandra baut man jedoch eine masterlose Architektur auf, in der die Knoten gleichgestellt sind. So kann jeder Knoten bei Apache Cassandra eine Anfrage verarbeiten, egal ob er lesen oder schreiben soll.
Stand: 16.12.2025
Es ist für uns eine Selbstverständlichkeit, dass wir verantwortungsvoll mit Ihren personenbezogenen Daten umgehen. Sofern wir personenbezogene Daten von Ihnen erheben, verarbeiten wir diese unter Beachtung der geltenden Datenschutzvorschriften. Detaillierte Informationen finden Sie in unserer Datenschutzerklärung.
Einwilligung in die Verwendung von Daten zu Werbezwecken
Ich bin damit einverstanden, dass die WIN-Verlag GmbH & Co. KG, Chiemgaustraße 148, 81549 München einschließlich aller mit ihr im Sinne der §§ 15 ff. AktG verbundenen Unternehmen (im weiteren: Vogel Communications Group) meine E-Mail-Adresse für die Zusendung von redaktionellen Newslettern nutzt. Auflistungen der jeweils zugehörigen Unternehmen können hier abgerufen werden.
Der Newsletterinhalt erstreckt sich dabei auf Produkte und Dienstleistungen aller zuvor genannten Unternehmen, darunter beispielsweise Fachzeitschriften und Fachbücher, Veranstaltungen und Messen sowie veranstaltungsbezogene Produkte und Dienstleistungen, Print- und Digital-Mediaangebote und Services wie weitere (redaktionelle) Newsletter, Gewinnspiele, Lead-Kampagnen, Marktforschung im Online- und Offline-Bereich, fachspezifische Webportale und E-Learning-Angebote. Wenn auch meine persönliche Telefonnummer erhoben wurde, darf diese für die Unterbreitung von Angeboten der vorgenannten Produkte und Dienstleistungen der vorgenannten Unternehmen und Marktforschung genutzt werden.
Meine Einwilligung umfasst zudem die Verarbeitung meiner E-Mail-Adresse und Telefonnummer für den Datenabgleich zu Marketingzwecken mit ausgewählten Werbepartnern wie z.B. LinkedIN, Google und Meta. Hierfür darf die Vogel Communications Group die genannten Daten gehasht an Werbepartner übermitteln, die diese Daten dann nutzen, um feststellen zu können, ob ich ebenfalls Mitglied auf den besagten Werbepartnerportalen bin. Die Vogel Communications Group nutzt diese Funktion zu Zwecken des Retargeting (Upselling, Crossselling und Kundenbindung), der Generierung von sog. Lookalike Audiences zur Neukundengewinnung und als Ausschlussgrundlage für laufende Werbekampagnen. Weitere Informationen kann ich dem Abschnitt „Datenabgleich zu Marketingzwecken“ in der Datenschutzerklärung entnehmen.
Falls ich im Internet auf Portalen der Vogel Communications Group einschließlich deren mit ihr im Sinne der §§ 15 ff. AktG verbundenen Unternehmen geschützte Inhalte abrufe, muss ich mich mit weiteren Daten für den Zugang zu diesen Inhalten registrieren. Im Gegenzug für diesen gebührenlosen Zugang zu redaktionellen Inhalten dürfen meine Daten im Sinne dieser Einwilligung für die hier genannten Zwecke verwendet werden.
Recht auf Widerruf
Mir ist bewusst, dass ich diese Einwilligung jederzeit für die Zukunft widerrufen kann. Durch meinen Widerruf wird die Rechtmäßigkeit der aufgrund meiner Einwilligung bis zum Widerruf erfolgten Verarbeitung nicht berührt. Um meinen Widerruf zu erklären, kann ich als eine Möglichkeit das unter https://kontakt.vogel.de/de/win abrufbare Kontaktformular nutzen. Sofern ich einzelne von mir abonnierte Newsletter nicht mehr erhalten möchte, kann ich darüber hinaus auch den am Ende eines Newsletters eingebundenen Abmeldelink anklicken. Weitere Informationen zu meinem Widerrufsrecht und dessen Ausübung sowie zu den Folgen meines Widerrufs finde ich in der Datenschutzerklärung, Abschnitt Redaktionelle Newsletter.
Fällt einer dieser Knoten aus, müssen die Daten von ihm an einem anderen Ort verfügbar sein – ohne Backup, weil das zu lange dauern würde. Die Lösung: Die Daten werden stattdessen vorläufig repliziert, bevor sie jemand benötigt. Mit Cassandra erstellt man dazu eine Art SQL-Datenbank, die den Replikationsfaktor definiert, um jedes Datenelement in der gewünschten Anzahl von Knoten zu replizieren. Dafür ist zusätzlicher Speicherplatz nötig. Dieser kostet allerdings wenig im Vergleich zu einem möglichen Reputationsverlust, Auftragsausfällen und einem langfristigen wirtschaftlichen Schaden. Zur Ausfalltoleranz trägt zudem wesentlich bei, dass sich ein Apache Cassandra Cluster selbst wiederherstellen kann.
NoSQL-Datenbank: Desaster-tolerantes System einsetzen
Das Aufsetzen und Warten eines Apache Cassandra Clusters verlangt Fachkenntnisse und ist aufwändig. Dies wird sich jedoch für Unternehmen rechnen, die ihre Daten nicht auf einem einzigen Server halten, sondern geografisch verteilen wollen. Die Nachteile, weder das Datenmodell einschränken noch Kaskadenoperationen durchführen zu können, kompensiert ihre schnell lesende und schreibende NoSQL-Datenbank.
Administratoren können den gesamten Cluster so konfigurieren, dass ein schnell verteiltes, Desaster-tolerantes System entsteht, welches genau auf ihre Situation zugeschnitten ist. Mittlerweile haben deshalb viele bekannte Top-Unternehmen Apache Cassandra oder seine kommerzielle Version, DataStax Enterprise, implementiert. Unter anderen vertrauen Apple, Netflix, Twitter, Sony, eBay, Walmart, FedEx und viele andere dem Flaggschiff unter den Cloud-Datenbanken. Es zeigt sich: Eine ausfallsichere Datenbank, die nicht „vollläuft“, ist für viele Unternehmen unterschiedlicher Branchen relevant.

:quality(80)/p7i.vogel.de/wcms/81/53/8153c6a6dabe6937623317648729fee8/univention-summit-20connect-202026-743x418v1.jpeg "Peter Ganten, CEO der Univention GmbH, sagt in seiner Keynote: Digitale Souveränität muss jetzt beginnen! (Bild: Univention GmbH)")
:quality(80)/p7i.vogel.de/wcms/76/5d/765d66719563df9fd3d38e49a40f6fa1/telekom-ki-fabrik-bild2-1200x675v1.jpeg "Bringen die neue KI-Fabrik der Telekom in München ans Netz: Ferri Abolhassan, CEO von T-Systems, Dieter Reiter, OB von München, Markus Söder, Ministerpräsident Bayern, Lars Klingbeil, Bundesfinanzminister und Tim Höttges, CEO der Deutschen Telekom. (Bild: Deutsche Telekom AG/Cindy Albrecht, Robert Dieth)")
:quality(80)/p7i.vogel.de/wcms/c4/0f/c40fc27b3ba9f4cb8921429a81e9fe88/deutsche-20telekom-t-20cloud-20public-16-9-1308x735v1.jpeg "Die Deutsche Telekom baut die T Cloud Public zur souveränen Cloud-Alternative aus. (Bild: Deutsche Telekom)")
:quality(80)/p7i.vogel.de/wcms/26/7f/267fe7086a35a99a8746d5328bc34387/souver-c3-a4nit-c3-a4t-antto-ai-adobestock-935874090-mitki-1197x673v1.jpeg "(Bild: © Antto-AI/stock.adobe.com - generiert mit KI)")
:quality(80)/p7i.vogel.de/wcms/ed/a3/eda36bff4eab74b47f38ae9c2f5962f8/cloud-erp-mahat-adobestock-835645806-mitkiv1.jpeg "(Bild: © mahat/stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/fa/a3/faa35b3be508b1bafeae8e481dad808c/hr-ipopba-adobestock-451361135-neu-780x439v1.jpeg "(Bild: © ipopba/stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/85/10/851074900a9e0eabf32944642cc2272f/adobestock-1270513612-vectorwin-colocation-996x560v1.jpeg "(Bild: © vectorwin/stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/4a/c3/4ac353ac9ecdfc9c07cb9cd559a578a0/genai-krot-studio-adobestock-1335835272-neu-1200x675v1.jpeg "(Bild: © Krot_Studio/stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/af/35/af35b7a70474e8d447c57993e0146b38/kit-quantentechnologien-karlsruhe-1230x691v1.jpeg "Die optische Schnittstelle für einen Quantenspeicher wird ein wichtiger Bestandteil von künftigen Quantennetzwerken sein. Der erste Teil davon wurde Anfang 2025 am KIT gebaut. (Bild: Markus Breig/KIT)")
:quality(80)/p7i.vogel.de/wcms/aa/09/aa0954018ba5f37cfdfcfa30ad809da7/quantenc--20www-freund-foto-de-adobestock-652196310-mitki-1067x600v1.jpeg "(Bild: © www.freund-foto.de/stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/7c/97/7c9771d964d17b3b15df85b23b81f41f/bundesdruckerei-pqc-personalausweis-16-9-1200x674v1.jpeg "Demonstrator des quantensicheren Personalausweises. (Bild: Bundesdruckerei GmbH)")
:quality(80)/p7i.vogel.de/wcms/8d/ec/8dec65346c49f21d4d8f3ca7a900470d/genai-krot-studio-adobestock-1335835272-neu-1200x675v1.jpeg "(Bild: © Krot_Studio/stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/e7/5c/e75c19a6fe17a3f6808c488cca304bd6/ki-security-igor-nazlo-adobestock-642102009-neu-997x561v1.jpeg "(Bild: © igor.nazlo/stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/3e/06/3e064c6104f3b0e5e74f8d5f06fbec86/kritis-leowolfert-adobestock-227539102-neu-878x494v1.jpeg "(Bild: © leowolfert/stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/58/43/5843c738a7f9e1643d5b6a125a538e5e/akamai-nocc-pano-16-9-1200x674v1.jpeg "Akamai betreibt ein eigenes Network Operations Command Center. (Bild: Akamai)")
:quality(80)/p7i.vogel.de/wcms/83/a8/83a862276bac51b761c5f27fe0d9e86b/ifs-cadillac-formel-1-team-bild2v1.png "Die Software von IFS unterstützt die Prozesse beim neuen Cadillac Formula 1-Team. (Bild: IFS)")
:quality(80)/p7i.vogel.de/wcms/1d/6f/1d6fa6c8604a36abf5a0bf7679e44c1b/genua-genuline-bild-3390x1908v1.jpeg "Mit einer FPGA-Hardwarebeschleunigung verbindet das BSI-zugelassene VPN-Gateway genuline von genua Standorte mit quantensicherer Verschlüsselung. (Bild: genua GmbH)")
:quality(80)/p7i.vogel.de/wcms/9e/88/9e884cac1f5ea1b21159ac7c3bf73b76/flexera-it-management-2026-freepik-7360x4142v1.jpeg "(Bild: Freepik)")
:quality(80)/p7i.vogel.de/wcms/26/45/264533841ff5d181c8770be1de0b3e7b/bastell-digitale-20zwillingsfabrik-16-9-1280x719v1.jpeg "(Bild: Baosteel)")
:quality(80)/p7i.vogel.de/wcms/6f/26/6f263aded473634af06b685ab52d310b/adobestock-1863853573-fakhra-death-of-prompting-ki-agenten-999x562v1.jpeg "(Bild: © Fakhra/stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/f0/f0/f0f0feec71fb8ec1d2f3d343e327f829/ki-2rogan-adobestock-717342439-mitki-932x524v1.jpeg "(Bild: © 2rogan/stock.adobe.com - generiert mit KI)")
:quality(80)/p7i.vogel.de/wcms/77/d4/77d4aa1f8a50822209edc6b443190333/telekonnekt-bild3-4128x2321v1.jpeg "Das Service-Team der Telekonnekt unterstützt Arztpraxen und Apotheken bei der Umstellung auf die neue Telematikinfrastruktur. (Bild: Stefan Prager)")
:quality(80)/p7i.vogel.de/wcms/62/1a/621a89cd2d07f631880e43cda889118b/adobestock-1644426553-karina-digital-health-969x545v1.jpeg "(Bild: © KARINA/stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/30/cd/30cd86fcb5d329cc823b8a6114db8189/dmea-20berlin-202025-16-9-2000x1124v1.jpeg "Die diesjährige DMEA findet vom 21. bis 23. April 2026 in der Messe Berlin statt. (Bild: © Messe Berlin GmbH)")
:quality(80)/p7i.vogel.de/wcms/64/f5/64f5013e4eedfa4f98b795e30cac7adc/it-sa-expo-26congress-eingang-3-2-1400x788v1.jpeg "(Bild: NürnbergMesse GmbH)")
:quality(80)/p7i.vogel.de/wcms/e6/db/e6dbf6cd77bbb7d46954d17450354c62/ot-oulaphone-adobestock-1069683089-5798x3264v1.jpeg "(Bild: © Oulaphone/stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/a2/b7/a2b78c24a10a843fe4456112371dff7d/cybersecurity-looker-studio-adobestock-563886800-neu-875x492v1.jpeg "(Bild: © Looker_Studios/stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/b4/07/b407aec50a1c555341b71483c58d954a/resilienz-srite-20khatun-adobestock-821261728-neu-880x495v1.jpeg "(Bild: © Srite Khatun/stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/0c/37/0c3795d561b32378f5a1728f3efcedaa/esker-scott-20mcdermott-16-9-1200x674v1.jpeg "Scott McDermott ist neuer Chief Financial Officer von Esker. (Bild: Esker)")
:quality(80)/p7i.vogel.de/wcms/46/b2/46b26d5ed883ada5b43309c2b4c76011/arbeitsplatz-exnoi-adobestock-808744861-mitki-996x560v1.jpeg "(Bild: © Exnoi/stock.adobe.com - generiert mit KI)")
:quality(80)/p7i.vogel.de/wcms/e7/c2/e7c24ae49b93587a03e144ce71866eaf/digitalisierung-wrightstudio-adobestock-235419903-neu-1500x843v1.jpeg "(Bild: © WrightStudio/stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/8e/b6/8eb6d3ea6cb30a574a210867044222ac/ki-sutthiphong-adobestock-657414716-neu-841x473v1.jpeg "KI Strategie AI Agents (Bild: © Sutthiphong/stock.adobe.com)")
")
")
")
:quality(80)/p7i.vogel.de/wcms/bb/d6/bbd63a686ca703165103c9c819e603b0/data-20center-amjad-adobestock-949675007-mitki-1067x600v1.jpeg "data-20center-amjad-adobestock-949675007-mitki-1067x600v1 (Bild: Amjad/Adobe Stock)")
:quality(80)/p7i.vogel.de/wcms/37/8f/378f2ba25a46599fec9be81f42fb1aff/adobestock-306938279-yurich84-datenschutz-compliance-automatisierung-datenbanken-1000x563v1.jpeg "adobestock-306938279-yurich84-datenschutz-compliance-automatisierung-datenbanken-1000x563v1 (Bild: © yurich84/stock.adobe.com)")